Tutorial¶
This tutorial will explain step-by-step how to use BEASTling to set up, configure, run and analyze a Bayesian phylogenetic analysis of language data. As an example, we will use a small dataset of lexical data for the Indo-European language family. This tutorial will only scratch the surface of using BEASTling, using BEAST, and Bayesian phylogenetic analysis in general. It should be a convenient first step, but you should make use of as many other resources as you can to learn how to use these tools and interpret the results. The official BEAST book is a great resource.
BEASTling is a command line tool. The actual analysis tool, BEAST 2, is most easily run from the command line interface as well. We will therefore begin by giving you a very short introduction to working with the command line, which you can skip if you are already familiar with this and go directly to Installation. If you have BEASTling and BEAST 2 installed and accessible from your CLI, skip further to Using BEASTling.
Fundamentals¶
While you may be used to driving applications by pointing and clicking with the mouse and very occasionally typing text, command-line interfaces (CLI) use text commands to drive computer programs.
In some sense similar to human language, these text commands must obey a specific syntax to be understood (but as opposed to human language, if you don’t follow the syntax strictly, nothing will happen), and this syntax powers compositionality, which makes automatising complex or repetitive tasks easier. In addition, the text representation means that command line instructions can be easily copied, shared, reproduced, and modified.
BEASTling was created to automatise complex tasks and improve reproduceability and adaptation for Bayesian inference on linguistic data, so it has naturally been implemented as a command line tool – and this part of the tutorial is there to ensure that BEASTling does not fail its goal to make using inference tools less daunting just by living on the CLI.
So here are some instructions to get you started using that powerful tool.
The CLI application, where you type commands and see their outputs, is called a shell.
The most common shell these days is bash (or variants thereof),
which is the default on Linux and Mac systems in the Terminal
application. By default, Windows systems only include the Command
Prompt, which you can start by looking for cmd.exe and running
that. The Command Prompt is far less flexible and user-friendly than
other available shells, but sufficient for running beastling.
If you are working under Windows, you will need a working Python installation to run beastling, for which you will install Anaconda in the next section. Anaconda gives you a Command Prompt set up to work more cleanly with its Python installation under the name Anaconda Prompt. For the matters of this introduction to the command line, Command Prompt and Anaconda Prompt are interchangeable.
Now, start your shell – open a Terminal application, start cmd.exe
or run an Anaconda Prompt, whichever is available to you. You should
now have a window that displays you some text – often some information
about you, then a directory name (where ~ means “your home
directory”) and then a prompt symbol ($ or >), before a cursor.
Type dir and press Enter. The shell should show you the contents of
the directory you are in, which is probably your home directory.
For the remainder of this tutorial, we will use the notation
$ echo Example Command
Example Command
to show you what to type on the command line and what to expect as output.
The two lines above mean that you should type echo Example Command
after the prompt symbol (which may be > instead of $, if you are
working on Windows), and expect the output Example Command.
Sometimes, we will abbreviate the expected output, and write [...].
It is important to know how to navigate the file system on the command line, otherwise you will be stuck running all analyses inside your home directory! So let us create a new directory
$ mkdir example_directory
and step inside with the cd (“change directory”) command.
$ cd example_directory
$ dir
As you can see, this directory is empty – on the bash, dir outputs
nothing, while it lists two <DIR>``ectories ``. and .. on
Windows. These two directories are special (they exist under Linux as
well, they just are not shown): they are this directory
example_directory itself, and its parent directory, where we have
just come from, respectively. We can use these special directories to
move up using cd:
$ cd ..
$ dir
[... The same output as before, and the new directory:]
example_directory
[...]
$ cd example_directory
Paths like this can be combined using /, so if you are inside example_directory,
$ cd ../example_directory
will do nothing. This knowledge should allow you to go from any
directory to any other directory on your hard drive, and on Windows,
you can use your other hard drive’s letter, such as D:, as a command
to change hard drives. (Under Linux, other hard drives etc. just
behave like any other directory, so you change hard drives like you
change directories.)
Unfortunately, the Command Prompt and bash understand
different languages. For example, while in bash, we might have
$ echo This text is put into a file. > file.txt
$ dir
file.txt
$ cat file.txt
This text is put into a file.
The cat command does not exist in Windows, as the Prompt will tell
you: ‘cat’ is not recognized as an internal or external command,
operable program or batch file. There is however a Windows command
called type that you can use in place of cat, which will output
the content of a file. In this tutorial, we will use the language of
bash to give coded examples, but where needed we will give a Windows
command or a way outside the CLI to achieve the same result.
Installation¶
BEASTling is written in the Python programming language, and BEAST 2 is written in Java 8. We will therefore first have to install these core dependencies.
Java 8¶
Java 8 can be downloaded from the official Oracle website. You only need the JRE, not the JDK, to use BEAST.
Please note that BEAST 2 will not work with Java 7 or earlier versions, so even if you already have Java installed, you may need to upgrade.
BEAST 2¶
Once you have a working Java 8 installation, download BEAST 2 from the official BEAST 2 website. The README file included in the package you download will include installation instructions for your operating system.
In addition to installing BEAST 2, you should probably install some of its extension packages. Without these, you will be very limited in the kinds of analyses you can run. You can read about installing BEAST packages here.
Python¶
Most current Linux distributions come with a pre-packaged Python
installation. If your python version (which you can see by running
python --version in a shell) is lower than 2.7, you will want to
upgrade your Python in the way you usually install new software.
If you want to run BEASTling on Windows, we recommend the Anaconda Python distribution. Download it here and run the Python 3.5 installer for your system.
BEASTling and its Python dependencies¶
If you want to control the details of your installation, refer to
the Installation instructions elsewhere in the BEASTling
documentation. Otherwise, BEASTling is available from the Python
Package Index, which
is easily accessible using the pip command line tool, so it will
be sufficient to run
$ pip install beastling
[...]
in order to install the package and all its dependencies.
All current Python versions (above 2.7.9 and above 3.4) are shipped
with pip – if you have an older version of Python installed, either
check how to get pip elsewhere,
consider upgrading your Python or check the Installation chapter
for alternative installation instructions.
Using BEASTling¶
First, create a new empty directory. We will collect the data and run the analyses inside that folder. Open a command line interface, and make sure its working directory is that new folder. For example, start terminal and execute
$ mkdir indoeuropean
$ cd indoeuropean
For this tutorial, we will be using lexical data, i.e. cognate judgements,
for a small set of Indo-European languages. The data is stored in CLDF
format in a csv file called ie_cognates.csv which can be
downloaded as follows:
$ curl -OL https://raw.githubusercontent.com/lmaurits/BEASTling/release-1.2/docs/tutorial_data/ie_cognates.csv
[... Download progress]
(curl is a command line tool to download files from URLs, available
under Linux and Windows. You can, of course, download the file
yourself using whatever method you are most comfortable with, and save
it as ie_cognates.csv in this folder.)
If you look at this data, using your preferred text editor or importing it into Excel or however you prefer to look at csv files, you will see that
$ cat ie_cognates.csv
Language_ID,Feature_ID,IPA,Value
[...]
it is a comma-separated CLDF file, which is a format that BEASTling supports out-of-the-box.
So let us start building the most basic BEASTling analysis using this
data. Create a called ie_vocabulary.conf using your favourite text
editor with the following content:
[model ie_vocabulary] model = covarion data = ie_cognates.csv—ie_vocabulary.conf
This is a minimal BEASTling file that will generate a BEAST 2 XML configuration file that tries to infer a tree of Indo-European languages from the dataset using a binary Covarion model.
Let’s try it!
$ beastling ie_vocabulary.conf
$ ls
[...]
beastling.xml
[...]
$ cat beastling.xml
<?xml version='1.0' encoding='UTF-8'?>
<beast beautistatus="" beautitemplate="Standard" namespace="beast.core:beast.evolution.alignment:beast.evolution.tree.coalescent:beast.core.util:beast.evolution.nuc:beast.evolution.operators:beast.evolution.sitemodel:beast.evolution.substitutionmodel:beast.evolution.likelihood" version="2.0">
<!--Generated by BEASTling [...] on [...].
Original config file:
# -*- coding: utf-8 -*-
[model ie_vocabulary]
model = covarion
data = ie_cognates.csv
Please DO NOT manually edit this file without removing this message or editing
it to describe the changes made. Otherwise attempts to replicate your
analysis using BEASTling and the above configuration may not be valid.
-->
[... Many xml lines describing the model in detail]
</beast>
We would like to run this in BEAST to test it, but the default chain length of 10,000,000 will make waiting for this analysis to finish tedious (over an hour on most machines). Because this is a small data set, we can get away with a shorter chain length (we will discuss how to tell what chain length is required later), so let’s reduce it for the time being.
[MCMC] chainlength=500000 [model ie_vocabulary] model=covarion data=ie_cognates.csv—ie_vocabulary.conf
While we are at it, we might as well give the output a more useful
name than beastling. The analysis we construct is only about the
Indo-European vocabulary, so we might as well name our output files
accordingly.
[admin] basename=ie_vocabulary [MCMC] chainlength=500000 [model ie_vocabulary] model=covarion data=ie_cognates.csv—ie_vocabulary.conf
While we are at it, we might as well give the output a more useful
Now we can run beastling again (after cleaning up the previous
output) and then run BEAST.
$ rm beastling.xml
$ beastling ie_vocabulary.conf
$ beast ie_vocabulary.xml
[...]
[...] BEAST v2.4[...], 2002-[...]
Bayesian Evolutionary Analysis Sampling Trees
Designed and developed by
Remco Bouckaert, Alexei J. Drummond, Andrew Rambaut & Marc A. Suchard
[...]
===============================================================================
[...]
Start likelihood: [...]
[...]
Sample ESS(posterior) prior likelihood posterior
[...]
BEAST will now spend some time sampling trees. Because this is a simple analysis with a small data set, BEAST should finish in 5 or 10 minutes unless you are using a relatively slow computer. When BEAST has finished running, you should see two new files in your directory:
$ ls
[...]
ie_vocabulary.log
ie_vocabulary.nex
ie_vocabulary.xml
[...]
ie_vocabulary.log is a log file which contains various details of each of the 10,000 trees sampled in this analysis, including their prior probability, likelihood and posterior probability, as well as the height of the tree. In more complicated analyses, this file will contain much more information, like rates of change for different features in the dataset, details of evolutionary clock models, the ages of certain clades in the tree and more.
ie_vocabulary.log is a tab separated value (tsv) file. You should be able to open it up in a spreadsheet program like Microsoft Excel, LibreOffice Calc or
Gnumeric.
Let’s look at the first few lines of the log file.
$ head ie_vocabulary.log
[... Numbers are stochastic and may vary
Sample prior likelihood posterior treeHeight
0 -11.466785941356303 -5434.4533277100645 -5445.920113651421 2.930099025192108
50 -14.507387085439145 -4948.559786139161 -4963.0671732246 2.8632651425342983
100 -13.715625758051573 -4588.294198523788 -4602.009824281839 2.8235811961563644
150 -14.455572518334662 -4353.763156917764 -4368.218729436098 2.720387319308833
200 -10.719230155244194 -4219.189086103397 -4229.908316258641 2.0137609414490942
250 -2.906983109341201 -4176.574925532654 -4179.481908641995 1.4462030568578153
300 -2.9491105164545837 -4027.5833312195637 -4030.5324417360184 1.4462030568578153
350 5.795184249496499 -3866.294505320323 -3860.4993210708267 0.6592039530882482
400 8.927313730401623 -3757.008703631417 -3748.0813899010154 0.5651416164402189]
(head is a command available in most Unix-based platforms like Linux and OS X which prints the first 10 lines of a file. You can just look at the first ten rows of your file in Excel or similar if you don’t have head available)
Don’t panic if you don’t see exactly the same numbers in your file. BEAST uses a technique called Markov Chain Monte Carlo (MCMC), which is based on random sampling of trees. This means every run of a BEAST analysis will give slightly different results, but the overall statistics should be the same from run to run. Imagine tossing a coin 100 times and writing down the result. If two people do this and compare the first 10 lines of their results, they will not see exactly the same sequence of heads and tails, and the same is true of two BEAST runs. But both people should see roughly 50 heads and roughly 50 tails over all 100 tosses, and two BEAST runs should be similar in the same way.
Even though you will have different numbers, you should see the same 6 columns in your file. Just for now, we will focus on the first five. The sample column simply indicates which sample each line corresponds to. We asked BEAST to draw 500,000 samples (with the chain_length setting). Usually, not every sample in an MCMC analysis is kept, because consecutive samples are too similar to one another. Instead, some samples are thrown away, and samples are kept at some periodic interval. By default, BEASTling asks BEAST to keep enough samples so that the log file contains 10,000 samples. In this case, this means keeping every 50th sample, which is why we see 0, 50, 100, 150, etc in the first column. If we’d asked BEAST to draw 50,000 samples instead, we’d haave to keep every 5th sample to get 10,000 by the end, so the first column would start with 0, 5, 10, 15, etc.
The next three columns, prior, likelihood and posterior, record the important probabilities of the underlying model: the prior probability of the tree and any model parameters, the likelihood of the data under the model, and the posterior probability which is the product of these two values. These probabilities are stored logarithmically, e.g. the probability 0.5 would be stored as -0.69, which is the natural logarithm of 0.5. This simply makes it easier for computers to store very small numbers, which are common in these analyses.
The fifth column, treeHeight, records the height of each of the sampled trees (the total distance along the branches from the root to the leaves). Later, we will provide calibration dates for some of the Indo-European languages, and then the treeHeights will be recorded in units of years, and these values will give us an estimate of the age of proto-Indo-European. However, in this simple analysis, we have no calibrations, so the treeHeight is in units of the average number of changes which have happened in the data, per feature, from the root to the leaves.
Log files like this one are usually inspected using specialist tools to extract information from them (such as the mean value of a parameter across all samples, which is commonly used as an estimate of the parameter). A tool called Tracer is commonly used for this task. We will discuss using Tracer later. In a pinch, you can use spreadsheet software like Excel to analyse one of these files, too. For now, let’s turn our attention to the other log file.
beastling.nex is a tree log file which contains the actual 10,000 sampled trees themselves. This file is in a format knows as Nexus, which itself expresses phylogenetic trees in a format known as Newick, which uses nested brackets to represent trees. If you open this file in a text-editor like Notepad and scroll down a little, you will be able to see these Newick trees. One of them might look like this:
tree STATE_0 = (((((1:0.0699,10:0.0699):0.1936,9:0.2635):0.0767,(2:0.1176,5:0.1176):0.2225):0.9013,(6:0.4338,((((7:0.0262,12:0.0262):0.0649,8:0.0911):0.1889,((15:0.0884,19:0.0884):0.1319,16:0.2203):0.0597):0.0817,17:0.3617):0.0721):0.8076):0.6963,(((3:0.0438,14:0.0438):0.0124,4:0.0563):0.3858,((11:0.0154,18:0.0154):0.0507,13:0.0661):0.376):1.4957):0;
As you can see, Newick trees are very hard to read directly, especially for large trees. Instead, these files can be visualised using special purpose programs, which makes things much easier. FigTree is a popular example, but there are many more. Let’s take a look at our trees!
Remember there are 10,000 trees saved in the beastling.nex file. When you open the file in FigTree, by default it will show you the first one in the file (which corresponds to sample 0 in the beastling.log file). There are Prev/Next arrows near the top right of the screen which let you examine each tree in turn. The first tree in the file is the starting point of the Markov Chain, and BEAST chooses it at random. So the first tree you are looking at will probably not look like a plausible history of Indo-European! Here is an example:
.. image:: images/tutorial_tree_01.png
Once again, you should not expect to see the exact same tree in your file, because the trees are randomly sampled. But you should have a random tree which does not reflect what we know about Indo-European. However, regardless of the random starting tree, the consecutive sampled trees will tend to have a better and better match to the data. Let’s look at the 10,000th and final tree in the file, which should look better (you don’t have to press Next 10,000 times! Use the “Current Tree” menu to the left of the screen):

Here the Germanic, Romance and Slavic subfamilies have been correctly separated out, and the Germanic family is correctly divided into North and West Germanic. You should see similar good agreement in your final tree, although the details may differ from here, and the fit might not be quite as good or may be a little better. Bayesian MCMC does not sample trees which strictly improve on the fit to data one after the other. Instead, well-fitting trees are sampled more often than ill-fitting trees, with a sampling ratio proportional to how well they fit. So there is no guarantee that the last tree in the file is the best fit, but it will almost certainly be a better fit than the first tree.
Just like tools like Tracer are used on log files to summarise all of the 10,000 samples into a useful form, like the mean of a parameter, there are tools to summarise all of the 10,000 trees to produce a so-called “summary tree”. One tool for doing this is distributed with BEAST and is called treeannotator. If you are an advanced command line user you may like to use the tool phyltr, which is also written by a BEASTling developer and uses the idea of a Unix pipeline. The image below shows a “majority rules consensus tree”, produced using phyltr. This shows all splits between languages which are present in at least 5,000 of the 10,000 trees. The numbers at each branching point show the proportion of trees in the sample compatible with each branching.
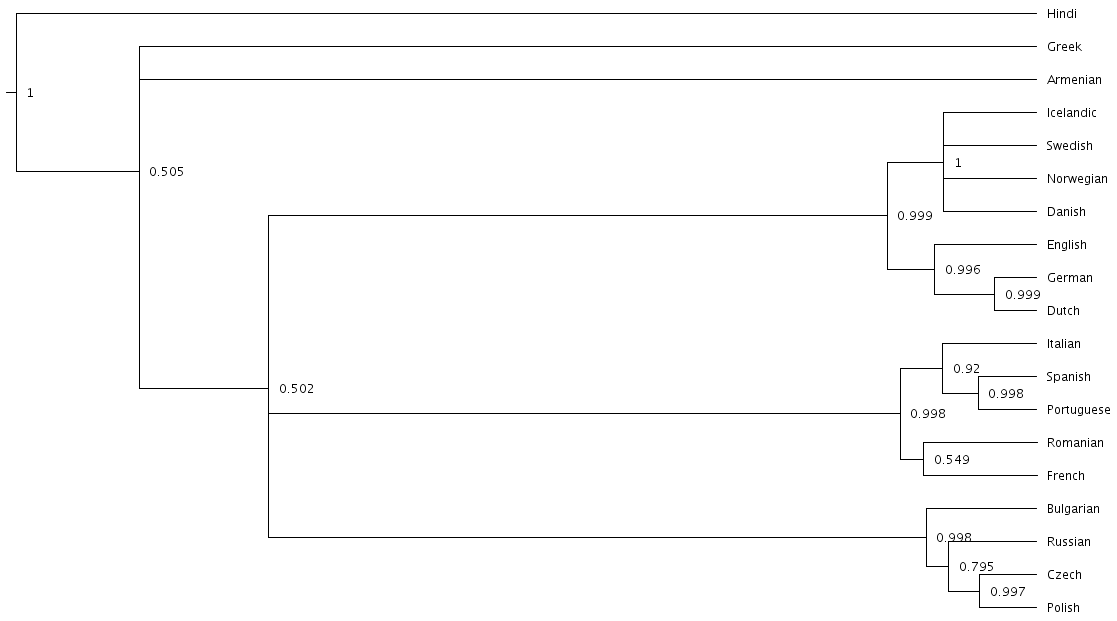
In this style of consensus tree, the tree may sometimes split into more than two branches at once (i.e. the tree is not a binary tree). For example, look at the Scandinavian languages. Here the tree splits into four languages. This is because the relationships among the Scandinavian languages is uncertain. All of the 10,000 trees in our posterior sample are binary trees, but this summary tree only shows relationships which are supported by at least half the trees. Perhaps in our 10,000 trees, Icelandic is most closely related to Norwegian 45,000 of them, to Swedish in 30,000 of them and Danish in 25,000 of them. None of these relationships is supported at least half the time, so the summary tree shows only a polytomy. But the posterior tree log file always contains full information about the uncertainty, i.e. by counting the relationships above we know that Icelandic is more likely to be related to Norwegian than Danish, and we know how much more likely (almost twice as likely).
Now, how much of this information is actually due to the cognate data, and not already in the model? For this simple model without clade constraints, age calibrations, interfering other models, and so on, the answer is easy: Nearly all of what we see (apart from the very rough shape of the tree, which is difficult to imagine generically) is generated from the data.
However, for more complicated analyses it is crucial to compare the posterior distributions of the analysis with the data to the prior, which is the same analysis without the data and tells us what we – according to the mathematical model we specified – actually believe before learning about the data.
BEASTling makes it very easy to sample the prior: Just specify
--sample-from-prior (or its even more concise synonym -p) on
the command line, and you get a beast XML file that can be used to
sample from the prior distribution of your model:
$ beastling -p ie_vocabulary.conf
$ beast ie_vocabulary_prior.xml
[...]
[...] BEAST v2.4[...], 2002-[...]
Bayesian Evolutionary Analysis Sampling Trees
Designed and developed by
Remco Bouckaert, Alexei J. Drummond, Andrew Rambaut & Marc A. Suchard
[...]
===============================================================================
[...]
Start likelihood: [...]
During the next steps of the tutorial, we will always sample from the prior prior to the posterior.
More advanced modelling¶
The BEASTling analysis we have used so far has a very short and neat configuration, but it is not based on a terribly realistic model of linguistic evolution, and so we may want to make some changes (however, it is always a good idea when working with a new data set to try to get very simple models working first and add complexity in stages).
The main oversimplification in the default analysis is the treatment of the rate at which linguistic features change. The default analysis makes two simplifications: first, all features in the dataset change at the same rate as each other. Secondly, it assumes that the rate of change is fixed at all points in time and at all locations on the phylogenetic tree. Both of these things are very unlikely to have been true about Indo-European vocabulary. BEASTling makes it easy to relax either of these assumptions, or both. The cost you pay is that your analysis will not run as quickly, and you may experience convergance issues.
Rate variation¶
You can enable rate variation by adding rate_variation = True to your [model] section, like this:
[admin] basename=ie_vocabulary [MCMC] chainlength=500000 [model ie_vocabulary] model=covarion data=ie_cognates.csv rate_variation=True—ie_vocabulary.conf
This will assign a separate rate of evolution to each feature in the dataset (each meaning slot in the case of our cognate data). The words for some meaning slots, such as pronouns or body parts, may change very slowly compared to the average, while the words for other meaning slots may change more quickly. With rate variation enabled, BEAST will attempt to figure out relative rates of change for each of your features (the rates across all features are assumed to follow a Gamma distribution).
Note that BEAST now has to estimate one extra parameter for each meaning slot in the data set (110), which means the analysis will have to run longer to provide good estimates, so let’s increase the chain length to 2,000,000. Ideally, it should be longer, but this is a tutorial, not a paper for peer review, and we don’t want to have to wait too long for our results.
[admin] basename=ie_vocabulary [MCMC] chainlength=2000000 [model ie_vocabulary] model=covarion data=ie_cognates.csv rate_variation=True—ie_vocabulary.conf
BEAST will now infer some extra parameters, and we’d like to know what they are. By default, these will not be logged, because the logfiles can become very large, eating up lots of disk space, and in some cases we may not be too interested. We can switch logging on by adding an admin section and setting the log_params option to True.
[admin] basename=ie_vocabulary log_params=True [MCMC] chainlength=2000000 [model ie_vocabulary] model=covarion data=ie_cognates.csv rate_variation=True—ie_vocabulary.conf
Now rebuild your XML file and run BEAST again, first sampling from the prior:
$ beastling -p --overwrite ie_vocabulary.conf
$ beast ie_vocabulary_prior.xml
[...]
Bayesian Evolutionary Analysis Sampling Trees
[...]
If you look at the new ie_vocabulary_prior.log file, you will
notice that many extra columns have appeared compared to our first
analysis. Many of these are the new individual rates of change for
our meaning slots. You should see columns with the following names:
featureClockRate:ie_vocabulary:I,
featureClockRate:ie_vocabulary:all,
featureClockRate:ie_vocabulary:ashes,
featureClockRate:ie_vocabulary:bark,
featureClockRate:ie_vocabulary:belly, etc. These are the rates of
change for the meaning slots “I”, “all”, “ashes”, “bark” and “belly”.
They are expressed as multiples of the overall average rate.
In the prior log file, these values should be all over the place, and have an average of one. This means that the model we specified is aware that some features may change faster than others, but it is not aware of which cognaters are less or more stable. Let us now see what the data adds to the picture:
$ beastling --overwrite ie_vocabulary.conf
$ beast ie_vocabulary.xml
[...]
Bayesian Evolutionary Analysis Sampling Trees
[...]
In my run of this analysis, the mean value of
featureClockRate:ie_vocabulary:I is about 0.16, meaning cognate
replacement for this meaning slot happens a bit more than 6 times more
slowly than the average meaning slot. This is to be expected, as
pronouns are typically very stable. On the other hand, my mean value
for featureClockRate:ie:vocabulary:belly is about 2.14, suggesting
that this word evolves a little more than twice as fast as average.
Features with a mean value of around 1.0 are evolving at the average
rate.
In addition to providing information on the relative rates of change for features, permitting rate variation can impact the topology of the trees which are sampled. If two languages have different words for a meaning slot which evolves very slowly, this is evidence the the languages are only distantly related. However, if two languages have different words for a meaning slot which evolves rapidly, then this does not necessarily mean they cannot be closely related. This kind of nuanced inference cannot be made in a model where all features are forced to evolve at the same rate, so the tree topology which comes out of the two models can differ significantly. Rate variation can also influence the relative timing of the branching events in a tree. If two languages share cognates for most meaning slots and differ in only a few, the rates of change of those few meaning slots give us some idea of how long ago the languages diverged.
Let’s look at our new trees, or rather, at a consensus tree:
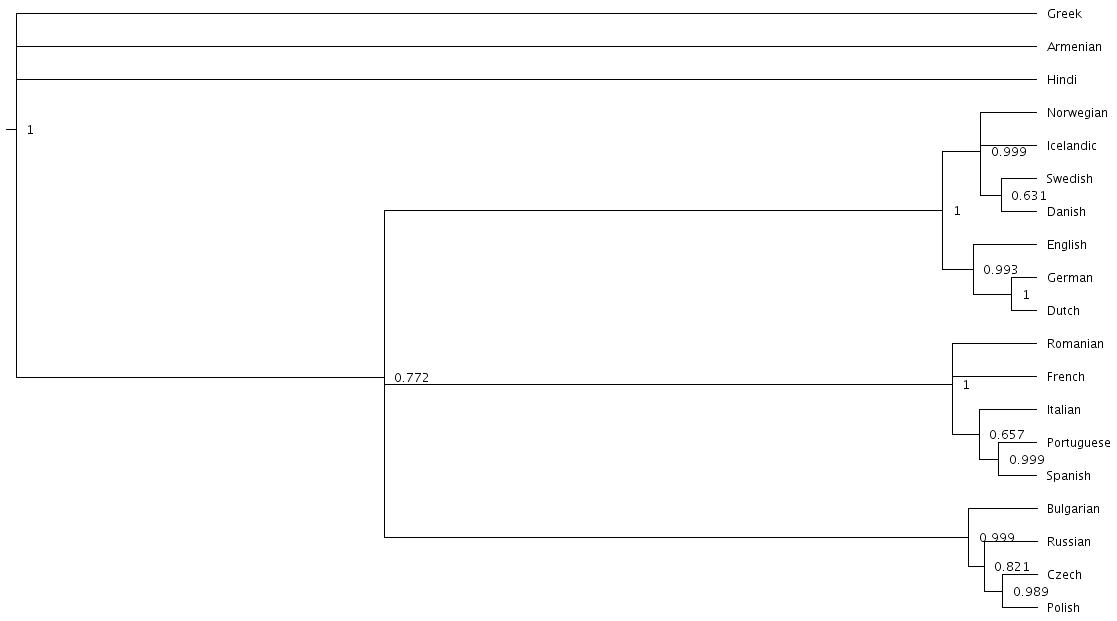
Notice that the Scandinavian languages are now a little bit better resolved - Swedish and Danish are directly related in about 6,310 of our 10,000 posterior trees, so the tree splits in two here now! This may be due to the rate variation (maybe some the cognates Swedish and Danish share belong to very stable meaning slots but BEAST could not use this information previously), or it might just be because we ran our chain for longer and got better samples (we are working a little “off the cuff” in this tutorial). Also notice that the Romance languages are a little less well resolved! Rate variation can cause this too. Perhaps the cognates shared by Romanian and French turned out to be for quickly changing meaning slots.
Like sampling from the prior, this incremental construction of the model is also a very useful strategy for phylogenetics. By comparing each level of added complexity to the previous one we see where a different model might be more or less compatible with our expectation. In this example we see minor, but present, changes in the tree topology and vast differences in rates, with in some cases quite tight confidence intervals. This means that it is well worth studying this model to consider whether it increases or decreases the overall realism of the analysis. Because Gamma rate variation appears compatible with our mental model and linguistic experience that there are words that are replaced faster or slower, and that pronouns belong to the slower class, we have a good justification for saying that our rate variation model adds realism and makes enough difference to justify the added model complexity – our data seems to be sufficiently informative about the different rates.
Clock variation¶
If you want the rate of language change to vary across different branches in the tree (which correspond to different locations and times), you can specify your own clock model.
[admin] basename=ie_vocabulary log_params=True [mcmc] chainlength=2000000 [model ie_vocabulary] model=covarion data=ie_cognates.csv rate_variation=True [clock default] type=relaxed—ie_vocabulary.conf
Here we have specified a relaxed clock model. This means that every branch on the tree will have its own specific rate of change. However, all of these rates will be sampled from one distribution, so that most branches will receive rates which are only slightly faster or slower than the average, while a small number of branches may have outlying rates. By default, this distribution is log-normal, but it is possible to specify an exponential or gamma distribution instead. Another alternative to the default “strict clock” is a random local clock, but relaxed clocks are more commonly used.
Note that we have left rate variation on as well, but this is not required for using a relaxed clock. Rate variation and non-strict clocks are two separate and independent ways of making your model more realistic.
Rebuild your XML file and run BEAST again in the now-familiar manner:
$ beastling -p --overwrite ie_vocabulary.conf
$ beast ie_vocabulary_prior.xml
[...]
$ beastling --overwrite ie_vocabulary.conf
$ beast ie_vocabulary.xml
[...]
Just like when we switched on rate variation, you should be able to
see that using a relaxed clock added several additional columns to
your beastling.log logfile. In particular, you should see:
clockRate.c:default, rate.c:default.mean,
rate.c:default.variance, rate.c:default.coefficientOfVariation
and ucldSdev.c:default. The first two new columns,
clockRate.c:default and ucldSdev.c:default, are the mean and
standard deviation respectively of the log-normal distribution from
which the clock rates for each branch are drawn. In this analysis,
the mean is fixed at 1.0, and this is due to the lack of calibrations.
You will see how this changes later in the tutorial. The next two,
rate.c:default.mean and rate.c:default.variance, are the
empirical mean and variance of the actual rates sampled for the
branches, which may differ slightly from the distribution parameters.
Finally, clockRate.c:default.coefficientOfVariation is the ratio
of the variance of branch rates to the mean, and provides a measure of
how much variation there is in the rate of evolution over the tree.
If this value is quite low, say 0.1 or less, this suggests that there
is very little variation across the branches, and using a relaxed
clock instead of a strict clock will probably not have enough impact
on your results to be worth the increased running time. High values
mean the data is strongly incompatible with a strict clock.
In my run of the prior, the
clockRate.c:default.coefficientOfVariation goes down to about
$ python -c ‘import pandas; pandas.read_csv(“ie_vocabulary_prior.log”, sep=”t”)[“clockRate.c:default.coefficientOfVariation”]’ 0
so we know that the other parts of the model are not interfering with the random clock.
Once again, we can look at a consensus tree to see how this change has affected our analysis.
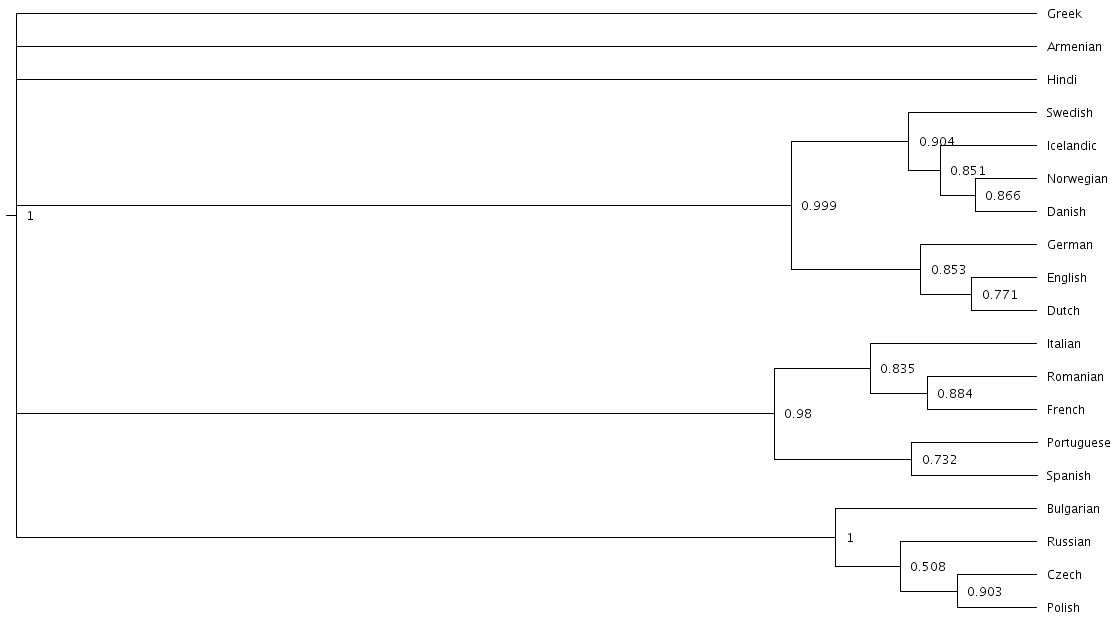
Notice that the Scandinavian and Romance subfamilies are now both completely resolved!
For more details on clock models supported by BEASTling, see the Clock models page.
Adding calibrations¶
The trees we have been looking at up until now have all had branch lengths expressed in units of expected number of substitutions, or “change events”, per feature. One common application of phylogenetics in linguistics is to estimate the age of language families or subfamilies. In order to do this, we need to calibrate our tree by providing BEAST with our best estimate of the age of some points on the tree. If we do this, the trees in our beastling.nex output file will instead have branch lenghts in units which match the units used for our calibration.
Calibrations are added to their own section in the configuration file. Suppose we wish to calibrate the common ancestor of the Romance languages in our analysis to have an age coinciding with the collapse of the Roman empire, say 1,400 to 1,600 years BP. We will specify our calibrations in units of millenia:
[admin] basename=ie_vocabulary log_params=True [mcmc] chainlength=2000000 [model ie_vocabulary] model=covarion data=ie_cognates.csv rate_variation=True [clock default] type=relaxed [calibration] French,Italian,Portuguese,Romanian,Spanish=1.4-1.6—ie_vocabulary.conf
Suppose we further wish to calibrate the common ancestor of our Germanic languages, this time a little more broadly. Proto-Germanic is generally believed to have developed during the pre-Roman Iron Age of 3,000 - 7,000 YBP:
[admin] basename=ie_vocabulary log_params=True [mcmc] chainlength=2000000 [model ie_vocabulary] model=covarion data=ie_cognates.csv rate_variation=True [clock default] type=relaxed [calibration] French,Italian,Portuguese,Romanian,Spanish=1.4-1.6 Danish,Dutch,English,German,Icelandic,Norwegian,Swedish=3-7—ie_vocabulary.conf
Once again we rebuild and re-run:
$ beastling -p --overwrite ie_vocabulary.conf
$ beast ie_vocabulary_prior.xml
[...]
Bayesian Evolutionary Analysis Sampling Trees
[...]
$ beastling --overwrite ie_vocabulary.conf
$ beast ie_vocabulary.xml
[...]
Bayesian Evolutionary Analysis Sampling Trees
[...]
Including this calibration will have changed several things about our output. First, let’s look at the prior log files, i.e. the results of our inference without any data involved. Below is a consensus tree.

We can see that, even without any language data included, the Romance and Germanic languages are grouped together in clades with support of 1.0, i.e. they are prefectly related in all 10,000 sampled trees. This is due to them being calibrated. However, notice that unlike previous consensus trees we have seen, there is no internal structure. We have told BEAST that German, Dutch, English, etc. are related, but without the cognate data there is no way for it to know that English is more closely related to German than it is to Icleandic. Therefore Both Romance and Germanic show up as highly polytomous in the consensus trees. Also notice that the Germanic clade is showing as older than the Romance clade, in accordance with our calibrations.
Let’s turn our attention now to the parameter log file. The most obvious
difference will be in the treeHeight column. Whereas previously
this value was in rather abstract units of “average number of changes
per meaning slot”, now it is in units of millenia, matching our
calibration. instead of a mean value of around 0.82, you should see a
mean value of something like 6.69. This is our analysis’ a priori
estimate of the age of proto-Indo-European (i.e. about 6,700 years). If
there is no data involved when we are sampling from the prior, where
does this estimate come from? It comes from the interaction of our
calibrations with the model’s tree prior. The Yule tree prior assumes
that language divergence events (“speciations”) occur at random interals
but with a constant probabilistic rate, like radioactive decay events.
Sometimes two divergence events may happen very shortly after one
another, or sometimes a long period of time may pass with no divergence,
but over a long enough timespan, we expect the total number of divergences
every, say, thousand years, to remain around the same. Since we have
told the model that proto-Romance broke up into five descendant languages
in about 1,500 years, and proto-Germanic broke up into 7 languages in a
longer (but less certain) time period, this puts some constraints on what
the possible constant rate of divergence might be. Regardless of what
the linguistic data says, we do not believe that Indo-European languages,
on average, diverge at rates so fast or so slow that the behaviours of
Romance or Germanic we have specified would be incredibly unlikely. If
in fact languages diverge at the sort of rates which would make these
behaviours perfectly typical, then this in turn implies what sort of
times would typically be required for all 19 languages in the datset to
diverge. This is where the 6,700 year estimate above comes from.
Because there is some uncertainty in our calibrations (i.e. we aren’t sure if Romance becan to disintegrate 1,400 or 1,600 years ago, and we have claimed to be very unsure about Germanic), and because the Yule tree prior is itself probabilistic (i.e. divergences happen with some average rate but there is always some chance of events happening unusually rapidly or slowly), our prior estimate of the age of Indo-European is similarly uncertain. The mean age of Indo-European in our 10,000 trees is 6,700 years, but we can get a plausible interval by seeing that 95% of the samples in our analysis are between 2.57 and 12.18, so the age of Indo-European could plausibly lie anywhere in this range. In general, the calibrations we add, and the tighter these calibrations becomes, the narrower the posterior estimate of the family age will be, as the divergence rate is more tightly constrained. This is not to say you should strive for lots of very restrictive calibrations. These can cause MCMC mixing problems, and at the end of the day the linguistic data should have a strong say in the results. It’s good if your prior is a little relaxed, so that it can accommodate the opinion of the data, but important that most of the prior probability is concentrated within what you consider a plausible range.
In addition to the treeHeight column, you should also see some new
columns, with somewhat unweildy names. One will be
mrcatime(French,Italian,Portuguese,Romanian,Spanish), and another
will have a similar form but will include the Germanic languages. These
columns records the age (in millenia BP) of the most recent common
ancestor of the Romance and Germanic languages in our analysis. Because
we placed a calibration on these node, you should see that almost all
values in these columns are between 1.4 and 1.6 or 3 and 7. The fits may
not be exact because of interaction between the two calibrations. In
my run of this analysis, I see a mean of 1.501 and a 95% HPD interval of
1.402 to 1.602 for Romance, indicating that our first calibration has
functioned exactly as intended. For Germanic I see a mean of 4.149 and
a 95% HPD interval of 2.186 to 6.271. This is not quite a perfect match
with what we specified, which was a mean of 5.0 and a HPD of 3.0 to 7.00,
but it is fairly close. Because there is only one divergence rate for
the whole tree, it is not always possible to achieve multiple precise
calibrations, as different calibrations may prefer different ranges of
divergence rate. This is one reason why it is very important to
sample from the prior and inspect the results, especially if you have
many calibrations. The interactions between the calibrations may in fact
force your prior to be something quite different from what you actually
want. In this case, things do not seem to be too bad.
Now let’s look at our actual results, i.e. the trees sampled from the posterior, not the prior, which take the data into account. The consensus stree is below.
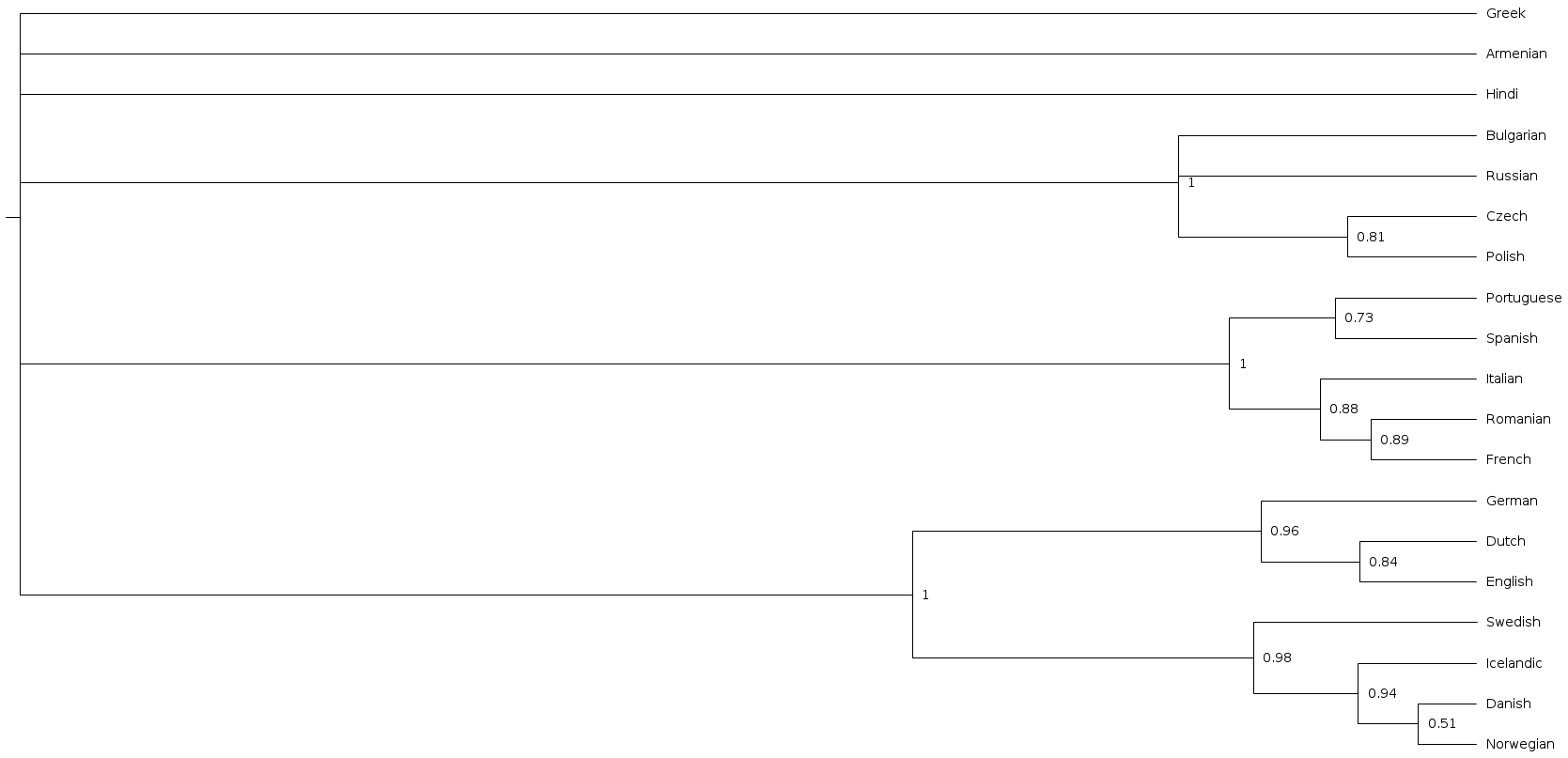
Notice that now the Romance and Germanic clades are internally resolved, and the Slavic clade has appeared again, because now the data can help identify those languages as being more similar to one another than to e.g. Greek and Hindi.
Let’s now look at the parameter log, and in particular at the treeHeight
column. Recall that when sampling from the prior, we got a mean age for
proto-Indo-European of 6,700 years, with a HPD interval of 2,570 to 12,580
years. How do our results compare when including the influence of data? I
get a slightly older mean of 8,900 years. This is still well within the
95% HPD range from our prior analysis, which means that the Yule tree prior
is quite happy at having to explain the entire IE family diverging from a
common ancestor in this time using the same overall average rate of
divergence it has to use to explain our Romance and Germanic calibrations.
But while the Yule would be even happier if the tree were a little younger,
there is enough lexical variation across the entire family’s data that the
Covarion subsitution model insists on an extra 2,000 years because it has
to be happy explaining the cognate replacement events that happen across
the entire tree and within Romance and Germanic using the same overall
average rate of linguistic evolution (with some allowance for variation
across the tree according to the the relaxed clock). Our prior sample is
a compromise between what the prior wants and what the data demands.
Again we can look at the 95% HPD interval for the age of proto-IE, and I
see 3,200 - 16,650 years. This is quite a broad range, which is not
unexpected here – we are using a very small data set (in terms of
both languages and meaning slots) and have only one internal
calibration. Serious efforts to date protolanguages require much more
care than this analysis, however it demonstrates the basics of using
BEASTling for this purpose.
We can also look at the posterior age estimates for the Romance and Germanic clades individually. My mean age for Romance is almost exactly the same as the prior, 1.502. This is not too surprising, as our calibration on Romance is very tight and there is not much room for the data to push it around. However, my mean age for Germanic is 3.4, or 3,400 years, about 500 years younger than the prior, and the upper limit of the 95% HPD interval is only 5,400 years, compared to about 6,300 years in the prior. This suggests that the data is hard to reconcile with Germanic being at least twice as old as Romance. Indeed, our calibration on proto-Germanic (which should be properly understood as a calibration on the time proto-Germanic began to disintegrate, not when the original language arose) is probably on the high side. If I run this analysis with only the calibration on Romance, the model estimates Germanic to be about 1,300 years old, suggesting that it is roughly as lexically diverse (as represented in this small data set, of course) as Romance. Of course, equal lexical diversity does not necessarily translate into equal age, but with only one calibration the model has no way to estimate how much variation in the rate of lexical evolution there can be from clade to clade. This small example demonstrates some of the difficulty of estimating linguistic divergence times using complex models. More calibrations are generally better than few, but calibrations must be well-justified and carefully chosen if the result is to be reliable.
Best practices¶
Bayesian phylogenetic inference is a complicated subject, and this tutorial can only ever give you a quick first impression of what is involved. We urge you to make use of the many other learning resources available for mastering the art. However, to help you get started we offer a very brief discussion of some important “best practices” you should follow.
Keep it simple¶
For serious linguistic studies, you will almost always end up using some model more complicated than the default provided by BEASTling, perhaps using multiple substitution models, rate variation, non-strict clocks and multiple calibrations in either time or space. Each complication brings an additional chance of problems, and at the very least means your analysis will take longer to run.
You should always begin a study by using the simplest model possible, even if it is not a perfect match to reality. Make sure the model runs with a strict clock, no rate variation and without any calibrations first. Add these details later one at a time to see what impact each one has on the results. If you encounter any problems, at least you will know which part of the model is the cause.
Sample from the prior¶
For serious linguistic studies, you will probably end up using a relatively complicated prior distribution. In particular, you may have many different age calibrations. As we saw in the section Adding calibrations, multiple calibrations can be tricky and you may end up specifying implicit age priors that you are not aware of and perhaps do not agree with. The Yule tree prior may also unintentionally add high prior support for some clades. For this reason, you should always sample from the prior and look at the sampled trees.
In addition to making sure that your prior does not contain any unintentional biases, you should also check that your prior and your posterior are substantially different. If you get similar clade suppors and clade ages in these two forms of your analysis, it means that your data is actually not very informative and you should not really believe your results.
Target ESS values (or “How long should I run my chains?”)¶
The essence of what BEAST does when it runs an analysis configured by BEASTling is to sample 10,000 trees (and 10,000 values of all parameters), and we use these samples as an estimate of the posterior distribution. This is true regardless of the configured chain length. If we run the chain for 10,000 iterations, then each one is kept as one of our samples. If we run the chain for 100,000 iterations, then only every 10th sample is kept and the others are thrown out. Since we get 10,000 samples either way, how do we know how long to set our chain length?
In order for our estimate to be a “good one”, we need to take a few things into account. The MCMC sampler sets the tree and all parameters to random initial values, and then at each iteration attempts to change one or more of these values. The state of the chain drifts away from the random initial state (which is probably a very bad fit to the data) and then one the values are a good fit, the chain wanders around the space of good fitting values, sampling values in proportion to their posterior probability.
So, one thing we need to be sure of is that our chain runs for enough iterations to get out of the initial bad fit and into a region of good fit. This is known as “getting past burn in”.
Another thing to consider is that we want our 10,000 samples to be roughly independent. Suppose we have a weighted coin and we want to estimate the bias. We can flip it 10,000 times and count the heads and tails and compute the ratio to get a good estimate of the bias. Suppose instead of flipping the coin ourselves, we give it to a coin-flipping robot. The robot isn’t very good at its job (but it’s trying its best!), and it only succeeds in flipping the coin every 5 tries. Instead of getting a sequence like this:
H, T, H, T, H, H, T, T, H, T
we get a sequence like this:
H, H, H, H, H, T, T, T, T, T, H, H, H, H, H, T, T, T ,T, T,…
Obviously, if we let the robot produce 10,000 samples for us, we will not get as good an estimate as flipping the coin ourselves. We are getting 10,000 samples, but intuitively, there is only as much information as 2,000 “real” samples, due to the duplications.
A complicated MCMC analysis is kind of like this not-so-good robot. Consecutive samples tend to be identical or very similar to one another, so if we just took the first 10,000 samples out of the chain after burn in, there might actually only be a very small amount of information in them and our estimate would not be reliable. Because of this, we need to run the chain for more than 10,000 iterations (sometimes much more) and only record every 10th or 100th or 1,000th sample in order to ensure good quality estimates. The more complicated your analysis, the harder the MCMC robot’s job becomes, so the longer the required chain length and the longer you have to wait for results. Very complicated analyses with very large data sets can easily take several days or even weeks to provide a good sample!
So, how do we know when we have run our chain long enough to get past the burn in, and spaced our samples out enough to get a reliable estimate? The Tracer program distributed with BEAST can help us with this task.
When you load a BEAST .log file in Tracer, in addition to seeing the mean value of all the columns in the log file, you can see the ESS, or Effective Sample Size. This tells you how many independent samples your 10,000 samples hold as much information as (in our coin-flipping robot example above, we said that the ESS of the 10,000 samples was about 2,000 because). As a rule of thumb, an ESS of below 100 is too low for a reliable estimate, and an ESS of 200 or more is considered acceptable. Accordingly, Tracer will colour ESSes below 100 red to let you know they are problematic, and ESSes below 100 and 200 yellow to let you know they are not quite ideal.